
Last week I attended Search Solutions, one of my favourite annual events where all aspects of search are covered from web to intranet to enterprise. The first speaker Sebastian Blohm from Microsoft spoke about a new personalised Clutter folder for email and how his team had first developed a global model and then developed a way for this to be tuned for each user. The system can then filter email that isn’t actually spam, but might not be important (e.g. a company-wide announcement about car parking) into the Clutter folder. Context and interaction patterns were just a few of the signals used in a probabilistic programming model. Marc Bron of Yahoo then described his work developing quality metrics for online adverts, including measurements of mobile friendliness and aesthetic quality. Filtering the 5% of ‘bad’ adverts can be shown to increase conversion by 10% and showing only the 20% most ‘beautiful’ adverts can increase it up to 60%. Qin Yin of Google was next to tell us about the development of an on-device search capability for Android devices, to find content that is locally stored or cached – useful when connection quality is bad for example. Although light on technical detail Qin Yin did describe the Firebase API that app developers can use to submit content to be indexed as memory-mapped files on Flash storage.
The next session was started by Graham Digby of Lexis Nexis on building a legal question answering system. This was a great pragmatic approach where XML content was marked up as answers and a simple query matching algorithm allowed auto-suggestion of likely questions based on what the user was typing. Although simple, this approach works well and his team are now looking at ways to further analyse the query using part-of-speech tagging. Jon Brassey of Trip Database was next describing the evolution of his system from a simple list of hyperlinks to searchable resources to a comprehensive searchable database of medical information. Interestingly his index is enhanced with a quality metric so data that has undergone systematic review is ranked higher in results.
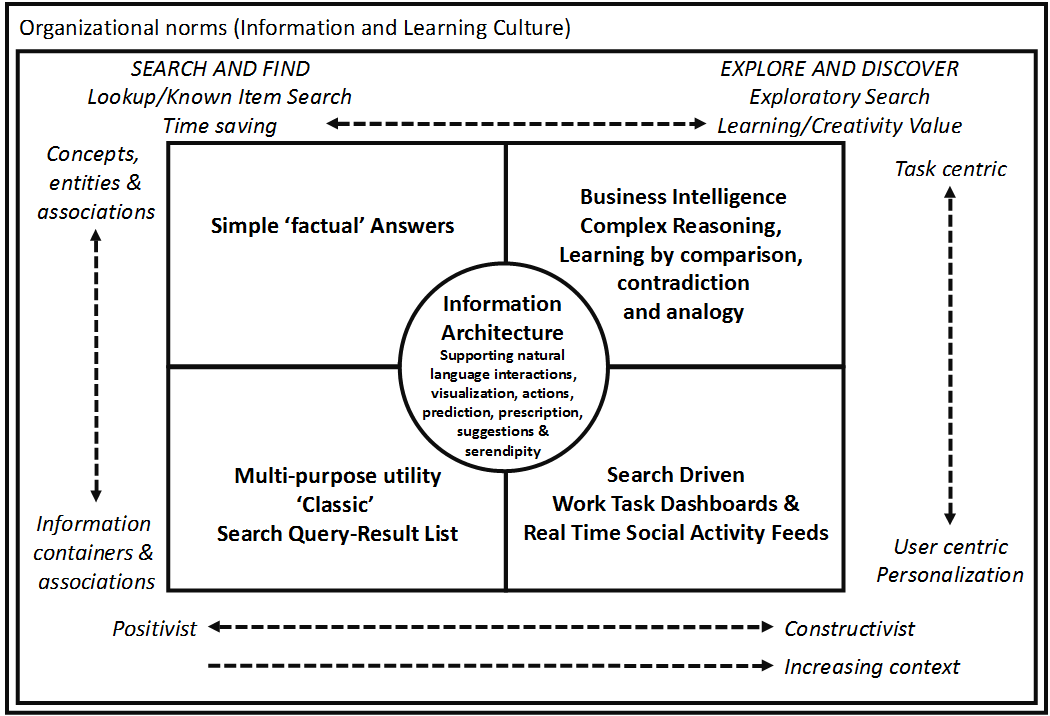
Vassilis Plachouras of Thomson Reuters started the next session, talking about a system to automatically generate textual descriptions of data, including some fascinating ordered lists of verbs used to describe trends – “plunge”, “rocketing” and “surged” all indicating a strong change. Next was Paul Cleverley who has carried out some fascinating research into the complaints made about enterprise search, identifying likely causal factors – it was interesting to see how technology was only responsible for 38% of the complaints. Paul also showed a fascinating model of the modality of search which with his permission I reproduce below:
I was up next to briefly describe the Lucene4IR workshop held in Glasgow recently to try to encourage the academic and industry communities to work closer on teaching and improving Lucene-based search engines. My slides are available here.
The next session started with an amusing talk by Matthew Karas, a veteran of speech recognition who has worked with Autonomy, the BBC and others on many applications. Apparently Welsh is far easier to automatically convert into text than English! Frederic Fol Leymarie finished up with a description of how shape-based search can be performed using lessons from research into human visual perception. A panel session followed which mainly covered the skills shortage mentioned in my talk, with a wider discussion of how non-technical ‘search managers’ are also in short supply.
The day finished with the inaugaral IRSG Search Industry Awards – I was honoured to have been asked to help judge these. The results have been announced by event chair Tony Russell-Rose, congratulations to all the winners. As ever this was a fascinating day covering many aspects of search and thanks must go to the BCS IRSG and all who spoke.










