
Last night I dropped in on the Unified Log Meetup at JustEat’s offices (of course, they provided lots of pizza for us all!). I’ve written about this Meetup before – as a rule the events cover logging and analytics at massive scale, with search being only part of the picture.
Joseph Francis from Skyscanner began with a talk about how they’ve developed a streaming data system to replace a monolithic SQL database for reporting and monitoring. Use cases include creating user timelines, data enrichment, JOINs and windowed aggregations and his team aim to provide a system that in-house developers can easily use for all kinds of analytics tasks. The system uses Apache Kafka as a highly scalable pipeline and Apache Samza for stream-based processing, as you can see (hopefully) in this photo of their architecture: 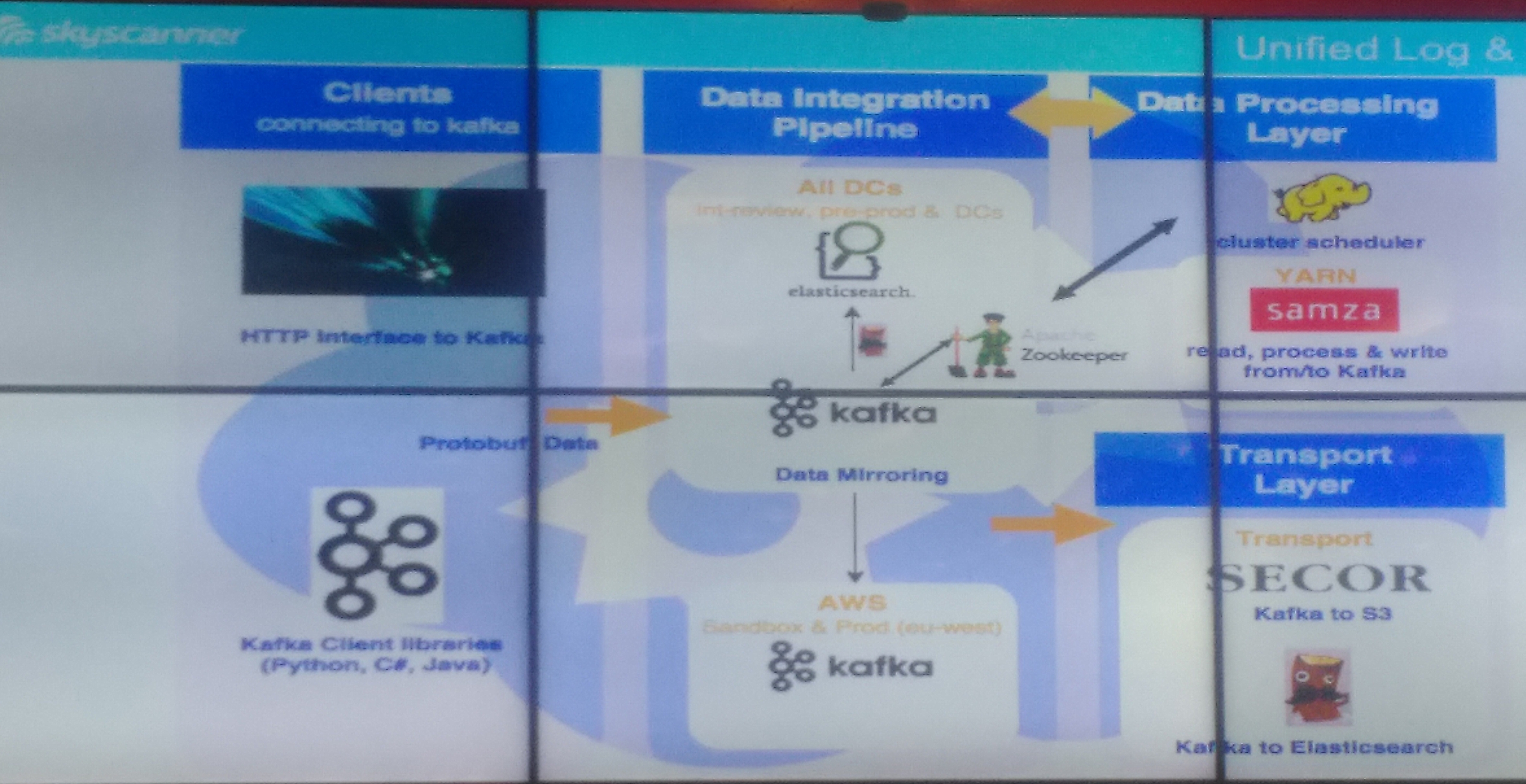
Elasticsearch provides querying capabilities and visualisations using Kibana. Joseph’s team have focused on making the system (and tasks that run on it) easy to deploy and use, with this currently managed using Ansible and TeamCity although they are now moving to a combination of Docker and Drone. As an aside, Skyscanner are also building autosuggest capabilities using Solr.
Next was Bruno Bonacci showing off his analytics system Samsara, inspired by a project to build analytics for Tesco’s HUDL tablet in only six weeks. With this short a timescale, Bruno took a pragmatic approach combining Kafka, Elasticsearch, Kibana and a number of custom components to allow relatively simple – but extremely fast – stream processing. He described how aggregation can either be done at ingestion time (which as you must store all the data you might need in separated chunks can end up taking up huge amounts of storage) or query time (which is far more flexible especially when you don’t yet know what questions you’ll need to answer). His custom processing module, Samsara Core, doesn’t use a built-in database for storing state (as Samza does) but rather uses an in-memory key-value store. For resiliency, this creates a log which is emitted as a Kafka stream. His approach seems to have huge performance implications – he has demonstrated Samsara running on a single core to be 72 times faster than a 4-core Spark Streaming system. Bruno and his team have released Samsara as open source and are working on new processing modules including sentiment analysis and classification. This is a fascinating project and a sign of the increasing need for high-performance streaming analytics. It would be interesting to see if our own work combining our stored query library Luwak with Samza could be combined with Samsara.
Thanks to Alex Dean of Snowplow for organising a very interesting evening and of course, to both the speakers.











Nice to see this “72x” improvement! Just for curiosity, Samza does have an in-memory KeyValue store coming out-of-the-box. Is there any key features that Samsara Core’s custom KV-store have that Samza’s build-in in-memory store does not provide? It would be good to know.
I don’t know I’m afraid – but Samsara is open source so it would be easy to look! I’m sure the authors of Samsara would be able to tell you.