The post Activate 2018 day 1 – AI and Search in Montreal appeared first on Flax.
]]>I was also pleased to notice our Luwak stored search library mentioned in the handout Bloomberg had placed on every seat!
The talks I attended after the keynote were generally focused on open source, Solr or search topics, but the theme of AI was everywhere. The first talk I went to was about Accenture’s Content Analytics Studio – which looks like a useful tool for building search and analytics applications using a library of widgets and a Python code editor. Unfortunately it wasn’t very clear how one might use this platform, with the presenter eventually admitting that it was a proprietary product but not giving any idea of the price or business model. I would much prefer if presenters were up-front about commercial products, especially as many attendees were from an open source background.
David Smiley‘s talk on Querying Hundreds of Fields at Scale was a lot more interesting: he described how Salesforce run millions of Solr cores and index extremely diverse customer data (as each one can customise their field structure). Using the usual Solr qf operator across possibly 150 fields can lead to thousands of subqueries being generated which also need to be run across each segment. His approach to optimising performance included analysing the input data per field type rather than per field, building a custom segment merge policy and encoding the field type as a term suffix in the term dictionary. Although this uses more CPU time, it improves performance by at least a factor of 10. David hopes to contribute some of this work back to Solr as open source, although much is specific to Salesforce’ use case. This was a fascinating talk about some very clever low-level Lucene techniques.

Next was my favourite talk of the conference – Kevin Watters on the Intersection of Robotics, Search & AI, featuring a completely 3D-printed humanoid robot based on the open source InMoov platform and MyRobotLab software. Kevin has used hundreds of open source projects to add capabilities such as speech recognition, question answering (based on Wikipedia), computer vision, deep learning etc. using a pub/sub architecture. The robot’s ‘memory’ – everything it does, sees, hears and how the various modules interact – is stored in a Solr index. Kevin’s engaging talk showed us examples of how the robot’s search engine powered memory can be used for deep learning, for example for image recognition – in his demo it could be trained to recognise pictures of some Solr commmitters. This really was the crossover between search and AI!
Joel Bernstein then took us through Applied Mathematical Modelling with Apache Solr – describing the ongoing work to integrate the Apache Commons Math library. In particular he showed how these new features can be used for anomaly detection (e.g. an unusually slow network connection) using a simple linear regression model. Solr’s Streaming API can be used to run a constant prediction of the likely response times for sending files of a certain size and any statistically significant differences noted. This is just one example of the powerful features now available for Solr-based analytics – there was more to come in Amrit Sarkar‘s talk afterwards on Building Analytics Applications with Streaming Expressions. Amrit showed a demo (code available here) using Apache Zeppelin where Solr’s various SQL-style operations can be run in parallel for better performance, splitting the job up over a number of worker collections. As the demo imported data directly from a database using a JDBC connector, some of us in the room wondered whether this might be a higher-performing alternative to the venerable (and slow) Data Import Handler…
That was the last talk I saw on Wednesday: that evening was the conference party in a nearby bar, which was a lot of fun (although the massive TV screen showing that night’s hockey game was a little distracting!). I’ll write about day 2 soon: videos of the talks are likely to be available soon on Lucidworks’ Youtube channel and I’ll update this post when they appear.
The post Activate 2018 day 1 – AI and Search in Montreal appeared first on Flax.
]]>The post Flax announces partnership with Apache Kafka creators Confluent appeared first on Flax.
]]>Kafka has been described as ‘TiVo for data’ – you can put pretty much any streaming data into Kafka, store it in a distributed and resilient way and then play it out again from any point. It’s highly scalable and integrates well with other Big Data tools such as Apache Hadoop. We’ve used Kafka and its sister project Apache Samza to develop prototype high-performance media monitoring systems and we’re also using it along with Elasticsearch, Logstash and Kibana (the ELK stack) to develop log monitoring and analysis systems. We’re hearing about many other potential uses of Kafka in the Big Data and Internet of Things ecosystems.
Our partnership with Confluent will allow us to work more closely together to provide a foundation for delivering better solutions faster for our customers based on Kafka and Confluent Platform, a complete and fully supported streaming data system based on Kafka and Hadoop.
“Kafka is creating a new paradigm for organizations and allowing businesses across industries to make informed, timely decisions from their data in real time” said Jabari Norton, VP Business Development at Confluent. “We are excited to include Flax among the ranks of a growing landscape of diverse partners and systems integrators committed to unlocking the potential of streaming data for their customers.”
We’ll be talking at the London Kafka meetup on April 13th if you’d like to find out more or discuss a potential Kafka project – if you can’t make it do get in touch.
The post Flax announces partnership with Apache Kafka creators Confluent appeared first on Flax.
]]>The post Unified Log Meetup – Scaling up with Skyscanner, Samza and Samsara appeared first on Flax.
]]>Joseph Francis from Skyscanner began with a talk about how they’ve developed a streaming data system to replace a monolithic SQL database for reporting and monitoring. Use cases include creating user timelines, data enrichment, JOINs and windowed aggregations and his team aim to provide a system that in-house developers can easily use for all kinds of analytics tasks. The system uses Apache Kafka as a highly scalable pipeline and Apache Samza for stream-based processing, as you can see (hopefully) in this photo of their architecture: 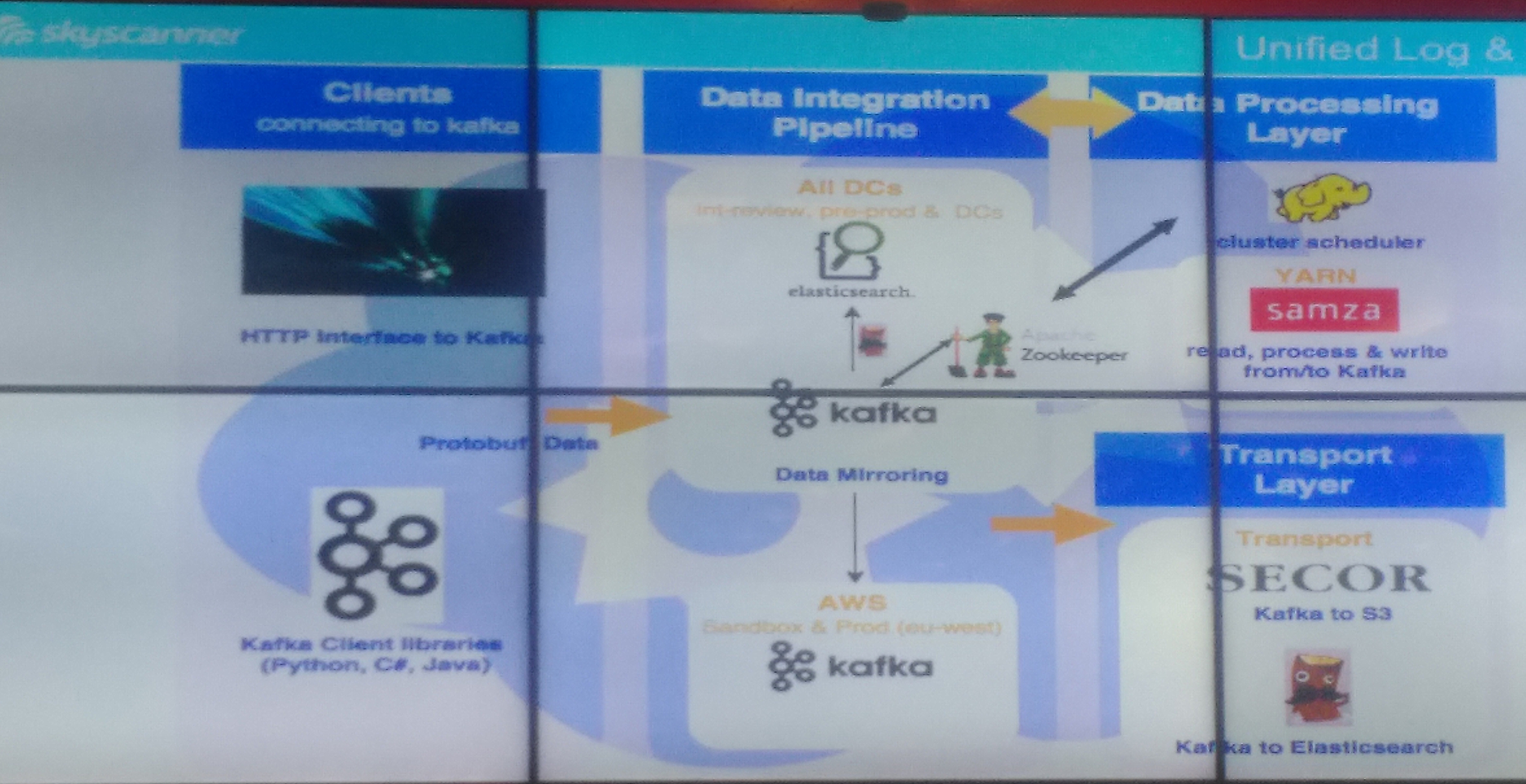
Elasticsearch provides querying capabilities and visualisations using Kibana. Joseph’s team have focused on making the system (and tasks that run on it) easy to deploy and use, with this currently managed using Ansible and TeamCity although they are now moving to a combination of Docker and Drone. As an aside, Skyscanner are also building autosuggest capabilities using Solr.
Next was Bruno Bonacci showing off his analytics system Samsara, inspired by a project to build analytics for Tesco’s HUDL tablet in only six weeks. With this short a timescale, Bruno took a pragmatic approach combining Kafka, Elasticsearch, Kibana and a number of custom components to allow relatively simple – but extremely fast – stream processing. He described how aggregation can either be done at ingestion time (which as you must store all the data you might need in separated chunks can end up taking up huge amounts of storage) or query time (which is far more flexible especially when you don’t yet know what questions you’ll need to answer). His custom processing module, Samsara Core, doesn’t use a built-in database for storing state (as Samza does) but rather uses an in-memory key-value store. For resiliency, this creates a log which is emitted as a Kafka stream. His approach seems to have huge performance implications – he has demonstrated Samsara running on a single core to be 72 times faster than a 4-core Spark Streaming system. Bruno and his team have released Samsara as open source and are working on new processing modules including sentiment analysis and classification. This is a fascinating project and a sign of the increasing need for high-performance streaming analytics. It would be interesting to see if our own work combining our stored query library Luwak with Samza could be combined with Samsara.
Thanks to Alex Dean of Snowplow for organising a very interesting evening and of course, to both the speakers.
The post Unified Log Meetup – Scaling up with Skyscanner, Samza and Samsara appeared first on Flax.
]]>The post Enterprise Search Europe 2015: Fishing the big data streams – the future of search appeared first on Flax.
]]>The post Enterprise Search Europe 2015: Fishing the big data streams – the future of search appeared first on Flax.
]]>The post Searching for opportunities in Real-Time Analytics appeared first on Flax.
]]>Real-Time Analytics is a field where sometimes vast amounts of data in motion is gathered, filtered, cleaned and analysed to trigger various actions to benefit a business: building on earlier capabilities in Business Intelligence, the endgame is a business that adapts automatically to changing conditions in real-time – for example, automating the purchasing of extra stock based on changing behaviour of customers. The analysis part of this chain is driven by complex models, often based on sets of training data. Complex Event Processing or CEP is an older term for this kind of process (if you’re already suffering from buzzword overflow, Martin Kleppman has put some of these terms in context for those more familiar with web paradigms). Tools mentioned included Amazon Kinesis and from the Apache stable Cassandra, Hadoop, Kafka, Yarn, Storm and Spark. I particularly enjoyed Michael Cutler‘s presentation on Tumra’s Spark-based system.
One of the central problems identified was due to the rapid growth of data (including from the fabled Internet of Things) it will shortly be impossible to store every data point produced – so we must somehow sort the wheat from the chaff. Options for the analysis part include SQL-like query languages and more complex machine learning algorithms. I found myself wondering if search technology, using a set of stored queries, could be used somehow to reduce the flow of this continuous stream of data, using something like this prototype implementation based on Apache Samza. One could use this approach to transform unstructured data (say, a stream of text-based customer comments) into more structured data for later timeline analysis, split streams of events into several parts for separate processing or just to watch for sets of particularly interesting and complex events. Although search platforms such as Elasticsearch are already being integrated into the various Real-Time Analytics frameworks, these seem to be being used for offline processing rather than acting directly on the stream itself.
One potential advantage is that it might be a lot easier for analysts to generate a stored search than to learn SQL or the complexities of machine learning – just spend some time with a collection of past events and refine your search terms, facets and filters until your results are useful, and save the query you have generated.
This was a very interesting introduction to a relatively new field and thanks to UNICOM for the invitation. We’re going to continue to explore the possibilities!
The post Searching for opportunities in Real-Time Analytics appeared first on Flax.
]]>